
https://arxiv.org/pdf/2305.18149.pdf
Introduction
AIによって生成された文章を検出するという試みは重要。ただし、現在ではSNSなどでの短文がLLMによって生成されているかを検出するのは困難である。一般的には短い回答は句読点、感情、フォーマリティで区別できる。しかし、極端に短いとそもそも人間の文章とAIの文章を区別することが本質的にできない。
この研究は、binary classificationに立ち戻り、PU Learningを考える。短文はラベル付けが難しいので、PUにしちゃおう、というモチベだ。しかもPUのフレームワークで長文も性能が上がった。
Multiscale Positive-Unlabeled Text Detection
PUにおけるText Detection
生成AIで偽ニュースを生成し、それを検出する分類器を作るという先行研究もある。また、GPT-2生成のテキストを検出するために、TF-IDF分類器や微調整されたRoBERTaなどを扱っている。
※ RoBERTaは以下の論文
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis,
Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized BERT pretraining approach.
CoRR, abs/1907.11692, 2019. URL http://arxiv.org/abs/1907.11692.
ただ、現行の検出器は長いテキスト向けで短いテキストではひどい精度となる。SNSなどに依存している現代の人にとってそれはfakeに対して脆弱であることを意味する。
二値分類に立ち返って考えてみた。Multiscale Text DetectionというタスクをPUとしてモデリングする。この問題では、人間によるコーパスをPositive、LLMによって生成されたテキストはUnlabeledとする(人間に似ているものもどうしてもあってしまうし、それはそれで人間と判定してしまうのも仕方ない)
PU Classificationの概観
わかっているのでだいたい端折る。Cost-sensitiveでやるよ。計算しやすいので。
実際、2つのクラスの距離は近そうなので、sample-selectionは向いてないと思う。
Kiryo2017のnnPUを使っている。
Multiscale PU 長さ依存のPU
Multiscale Text Detectionでクラス事前確率 を定数として固定しないというアイディアを考える。テキスト長でこれが変わってしまうからだと。
テキストの長さに応じたクラス事前確率を使った、新たなロスであるを定義した。 である。
まず、コーパスから各文章の出現確率を推定しないといけない。ここで、 は文字列(というかトークン列)が生成AIによってつくられたか、人間によってつくられたかを表す の値を示している。これを最適に定義する。
この論文は次のように前から順にある関数 でうまくできるように生成する、Recurrent Language Modelに従うと仮定した。
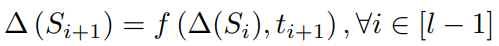
NLPでは、単語はそれぞれ(最低1つ最大複数の)のトークンにまず分ける。短文は、各トークンにまず分ける。各トークンはそれぞれ、
- Positive=「AIによってほとんど生成されることはないだろう」
- Unlabeled=「AIも生成するし人間も使う」
の2つに分類できる。
そして、積み重ねてきた各トークンがAIっぽい、人間っぽいという属性を持つ中、総合的にAI生成か人間が書いたのかを判断するということが必要である。
そして各トークンが同じ重さで文全体の判定に寄与する。よって、具体的なの更新は以下のようになる。
今までの結果と同じ重みで、今のトークンについての判断を加えて平均する。
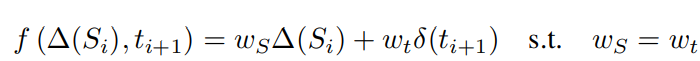
の実装として、PN Learningならば、Positiveなら , それ以外なら とおく。これを各トークンごとに積み重ねながらから溢れないようにする。
スタートのからスタートする。完全にPositive=人間が書いたと思える状態から始める。
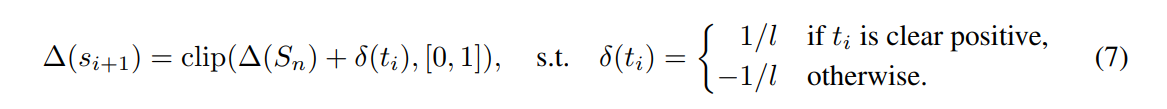
これによって、というPositiveだと思える期待値について、個の状態に離散化できる。
まず、全トークンの中で人間だけが生成するとわかっているトークンは の確率で出現することがわかっているとする。よって、Uのトークンはの確率でPに移動し、の確率でNに移動すると考える。
そして、具体的なその動きをすべて動的計画法のようにトレースすることで、最終的な期待値を計算することにあたる。
上の例だと、
- 1つ目はUだが例外的に上限があるのでのみ。
- 2つ目はUなので、の確率でPへ行き、それ以外の確率ででNへ行く。
- 3つ目はPで確定で、1の確率でPへ行く。
- 4つ目は2つ目と同様…
最終的に、以下のように長さで遷移が組めるとわかる。
最後に、 と乗じてあげることで、
とすることで、結果的にシミュレートして全部の集計ができる。
これによって、あるテキストについて、そのClass Priorのを推定できる。
これをPとラベル付けされている(つまり人間が使うとなっている)サンプルごとにClass Priorを推定させて、nnPUの式に入れる。
そして、最終的に使っているのは以下のように、PN損失と加重平均(ハイパーパラメタ)で組み合わせたもの。
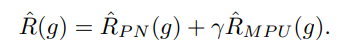
Text Multiscaling
長い段落しか与えられないとき、そこから短文をどうやって切り出すのかについても考えた。結論は、ランダムに独立に(ベルヌーイ分布で)各文章を削り落とすかを決める。短文を学習するため、文脈を除外して考えた。
Experiment
データセットとしてはTweepFakeとHC3を使う。
- TweepFakeは、AIで生成したテキストかどうかを識別するもの。
- HC3も同様。これは英語と中国語両方存在する。
- backboneはBERTとRoBERTaを使う。